Breaking Down Docker Containers
Understanding the importance of namespaces, cgroups, and access control


Unless you’ve been living under a rock, you’ve noticed that containerization has taken over the world.
Linux containers have become a popular method to package and deploy applications in a lightweight and portable manner. However, for those new to containerization, the technical concepts and jargon can be overwhelming.
In this post, I’m going to peel back the layers and take a closer look at the building blocks of Linux containers. I’ll explain what they are, how they work, and why they’re important for containerization.
By the end of this guide, you will have a better understanding of these key concepts and be well on your way to creating and managing your own Linux containers.
Before I dive too deep, it’s important to ask the question: what even are containers?
To understand containers, you need to understand processes.
A process is an instance of a computer program running on a machine. A typical process has a lot of freedom and access. It can talk to other processes, read/write data that another process has created, and interact with the operating system with little to no restrictions.
Why do you need to understand processes to understand containers?
To put it simply, containers don’t exist. A container is just an isolated process. In layman terms, a container is just a process with extra steps.
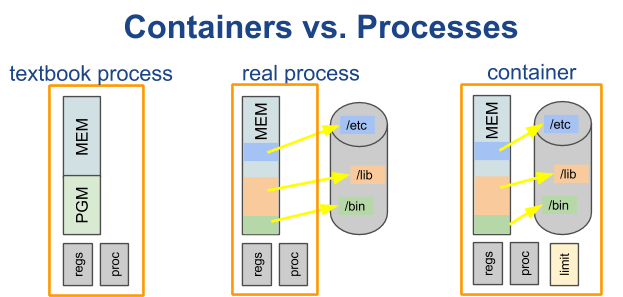
To an operating system, a container looks like any other process. But while a container runs like any other process, it doesn’t think it’s one.
Containers think that they’re their own machines. They have their own isolated filesystem, user, and network systems.
This makes them very portable. A containerized computer application can easily run on any server with a modern operating system.
The same can’t be said for a non-containerized application. Hence why a company like Slack has to build a different version for Windows, Mac, and Linux.
Containers also have resource restrictions that limit how much of the host operating system they can use up. This makes it possible to run tens, hundreds, or even thousands of containers in a single server.
So how does an operating system isolate a process in order to turn it into a container?
There are three foundational Linux features that enable containers to exist. So let’s explore each one.
Namespaces
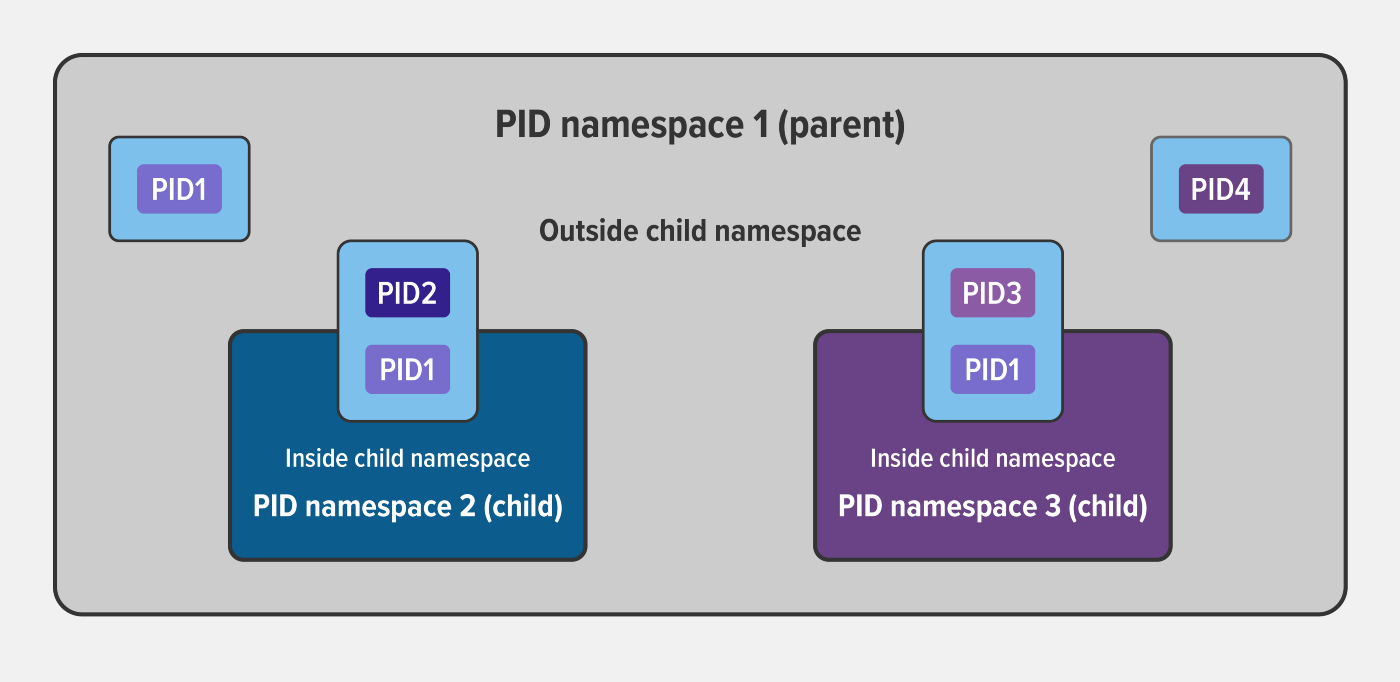
Namespaces allow a group of processes to see one set of resources while a different group of processes see a different set of resources.
I know that was wordy, so let’s break it down a bit.
You can think of a namespace like a fancy gated community. There are certain resources — pools, parks, facilities, etc — that only the homeowners in that community can access (unless you’re sharing a house in that fancy community with 14 other people, but that’s a story for a different time).
One gated community won’t be able to access the resources of a different gated community.
Think of the houses in that community like processes, and the shared community pool like a namespaced resource in the kernel that only those processes can see and use.
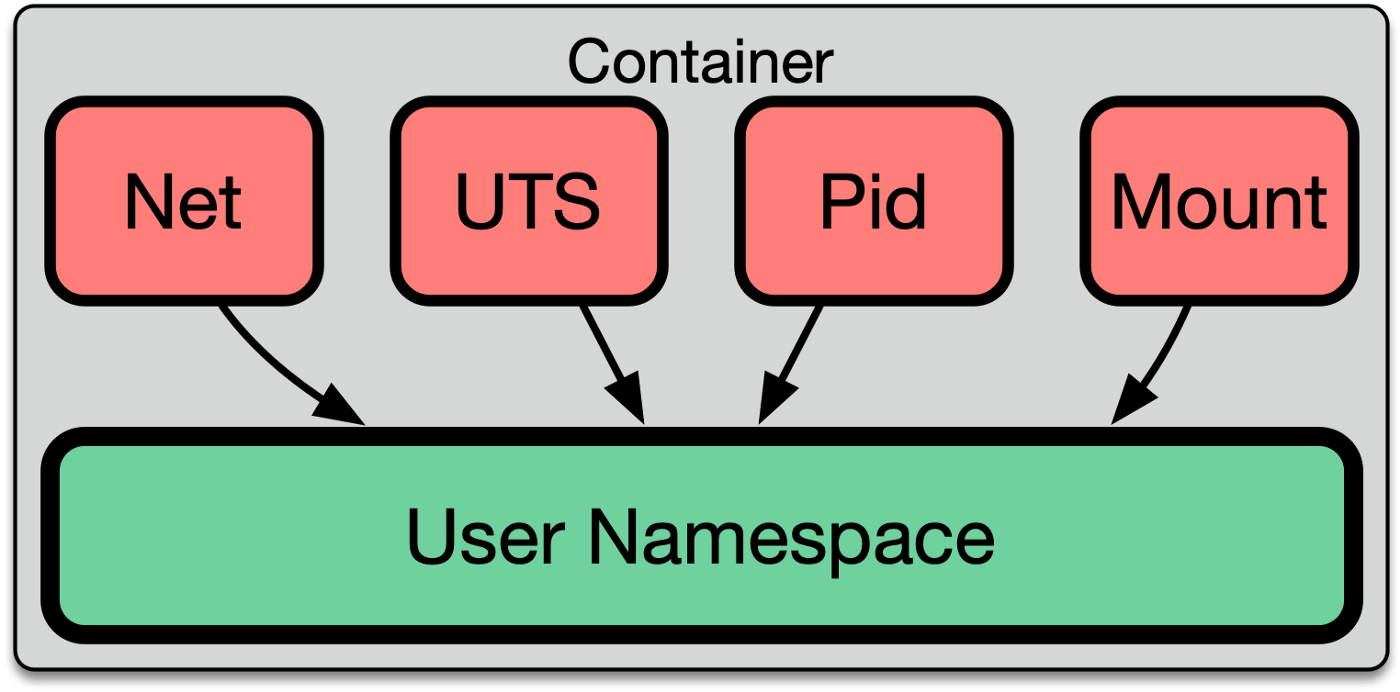
There are 7 main resources that can be namespaced:
1️. USER: A user namespace has its own set of user and group IDs that the operating system uses to assign to processes. In particular, this means that a process can run as the root user within its user namespace even if it’s not the root in other namespaces.
2️. PID: A process ID (PID) namespace assigns a set of PIDs to processes that are independent from the set of PIDs in other namespaces.
3️. NET: A network namespace has an independent network stack: its own private routing table, set of IP addresses, socket listing, connection tracking table, firewall, and other network related resources.
4️. MNT: A mount namespace has an independent list of mount points. This means that you can mount filesystems in this namespace without affecting the host. This is how docker containers can each have their own volumes.
5️. IPC: An interprocess communication (IPC) namespace has its own resources that allow processes to communicate with one another. For example, POSIX message queues.
6️. UTS: A UNIX Time Sharing (UTS) namespace allows a single system to appear to have different host and domain names from the host system. This is useful in scenarios where multiple containers need to have their own unique hostname, such as in a cluster or multi-tenant environment.
All of these namespaces are used by container engines, like Docker, to isolate processes and turn them into containers.
For those of you wondering what the 7th resource is, it’s control groups (cgroups). cgroups also happen to be the second building block of containers.
cgroups
Containers wouldn’t have ever become as popular as they are if it wasn’t for Linux control groups (cgroups). cgroups were started at Google in 2006 and merged into the Linux kernel in 2008.
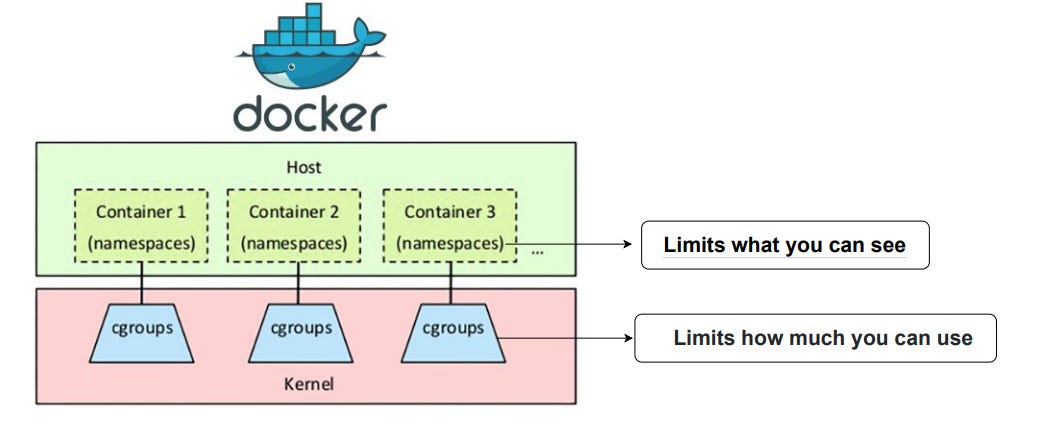
cgroups limit, account for, and isolate the resource usage by a group of processes. These resources include CPU, memory, disk, I/O, etc. Container technologies, like Docker and Podman, use them to limit the resource usage of containers so they don’t overwhelm the host system.
cgroups help prevent the “noisy neighbor” issue, where one process hogs up all the resources and causes other processes to starve and degrade. This allows multiple containers to exist on one host without issue. Any containers that exceed the limits defined by their cgroups are subject to termination to preserve the host server and prevent outages.
Linux namespaces limit what a container can see while cgroups limit what a container can use. When used together, they isolate a process and turn it into a container.
However, there’s still a crucial aspect missing: security.
Access control addresses that.
Access Control
Namespaces and cgroups provide a basic level of DDOS prevention and limit the attack surface to the host. But in certain scenarios, additional security measures are necessary. In particular, when running workloads and applications from untrusted users on cloud providers.
One way to add extra security is through access control.
Access control limits the access a container has to the host system, such as which files it can access and which system calls it can make. Some popular security systems that can be used to increase container security include:
🛡️ AppArmor: a mandatory access control system that assigns per-program profiles to restrict the capabilities of individual programs.
🕵️ SELinux (Security-Enhanced Linux): another mandatory access control system that provides fine-grained control, but can be complex to set up. It was originally created by the NSA and merged into the Linux kernel in 2003.
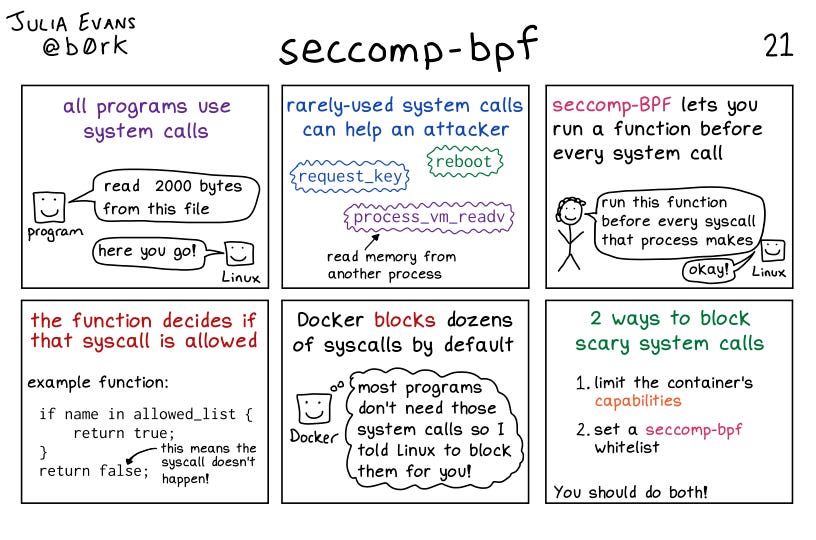
🖥️ seccomp (Secure Computing Mode): a Linux kernel feature that restricts system calls made by programs, making it a simpler and lightweight alternative to AppArmor and SELinux, useful in situations where only a limited set of system calls need to be restricted.
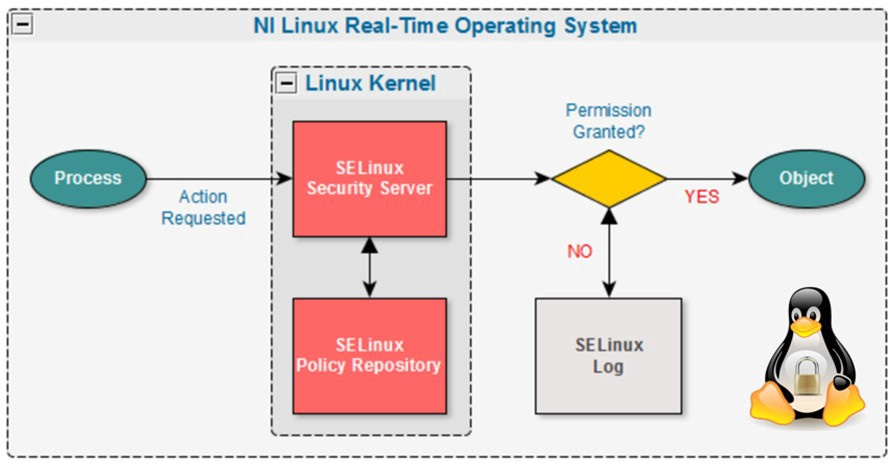
By default, container engines like Docker do not use access control systems, but they can be enabled. seccomp is available on all Linux servers while AppArmor and SELinux are only available on distributions that have them enabled.
Dedicating time to set up these access control measures can help to ensure the security of containerized workloads and applications and is a worthwhile investment.
By limiting system calls and restricting access to resources on the host system, access control makes it more difficult to compromise containers and reduces the blast radius of an attack.
At the core of containerization are namespaces, cgroups, and access control.
These fundamental pieces allow for the isolation and management of resources within a container, ensuring that each container has its own set of resources, while also preventing interference between different containers and the host system. Understanding how these concepts work is crucial for creating and managing containers in a secure and efficient way.
The container ecosystem is thriving and expanding. Docker, Kubernetes, Istio, microservices, and much more. New technologies and concepts are being created at a rapid pace. It can feel easy to be left behind in this new paradigm shift.
However, by understanding the building blocks of containers and container technology, everything else falls into place.